Uge 45 – Evaluering af LLM-modeller og reduktion af hallucinationer
Dato: 07-11-2025 | Uge: 45
Kontekst
Backend-udvikling og API-designMachine Learning og AI
Mål
Undersøge risiko for hallucinationer i LLM-output og evaluere hvilke modeller, der bedst understøtter strukturerede outputs og JSON-schema. Implementere LLM ved at refaktorere HLD og LLD.
Proces
Læse op på teknikker til reduktion af hallucinationer, udarbejde krav til modellen og evaluere Gemini, Claude og GPT-4.1 via praktiske tests.
Resultat
Som tidligere nævnt i min portfolio ( Uge 41 – del 2 vurderede jeg, at det ville give god mening at gennemføre et eksperiment, hvor en Large Language Model (LLM) beriger OCR-data med yderligere metadata. Når man arbejder med LLM’er, er der flere forhold, man skal tage højde for, og et af de vigtigste er, hvordan man reducerer risikoen for hallucinationer i modellens output.
Hallucination opstår, når modellen “finder på” plausible, men forkerte oplysninger baseret på sandsynligheder i sit træningsmateriale. En LLM vil altid forsøge at give et svar – også selvom den mangler nødvendig viden. I modsætning til mennesker udviser modellen ikke usikkerhed, og den kan fortsætte med at generere fejlagtigt indhold uden at være klar over det selv. Dette kan føre til, at én hallucination efterfølges af yderligere påstande, der understøtter det oprindelige fejlagtige svar (kilde: LLM hallucinations – forklaring).
Der findes ingen metode, der fuldstændigt eliminerer hallucinationer, men en række tilgange kan reducere forekomsten markant:
-
Retrieval-Augmented Generation (RAG)
Modellen får adgang til opdaterede fakta i runtime, som hentes før der genereres et svar. -
Fine-tuning og alignment
Modellen trænes på domænespecifikke data og kan instrueres i at svare mere forsigtigt. -
Prompt engineering
Input formuleres med kontekst, regler, eksempler og eksplicitte begrænsninger. -
Rule-based post-processing og guardrails
Backend kan validere eller korrigere modellens output. -
Confidence scoring
Modellen estimerer selv sikkerheden for sit svar. -
Self-reflection og iterative refinement
Modellen evaluerer sit eget svar og forbedrer det gennem iteration.
Krav til modellen
På baggrund af disse hensyn opstillede jeg følgende krav til den LLM, der skal anvendes i projektet. Modellen skal kunne:
- returnere output i et JSON-schema
- klassificere en maskine ud fra et modelnummer
- modtage en prompt med indbygget kontekst, eksempler og værn
- være gratis eller have nok credits til et Proof of Concept (min. 100 gratis kald)
De modeller, der bedst opfylder kravene, er:
- GPT-4.1
- Claude 3.5 Sonnet
- Gemini
Alle tre modeller understøtter strukturerede outputs og er stærke i kontekstforståelse.
Strukturerede outputs og JSON-schema
Strukturerede outputs giver:
- forudsigeligt output, som er let at parse
- garanti for format og datatyper
- mulighed for programmatisk håndtering af afvisninger
- ingen tekst udenfor JSON
- ingen outputs i forkert format
JSON-schema fungerer som en kontrakt mellem backend og LLM. Modellen må kun returnere værdier, der stemmer overens med schemaet.
Billede
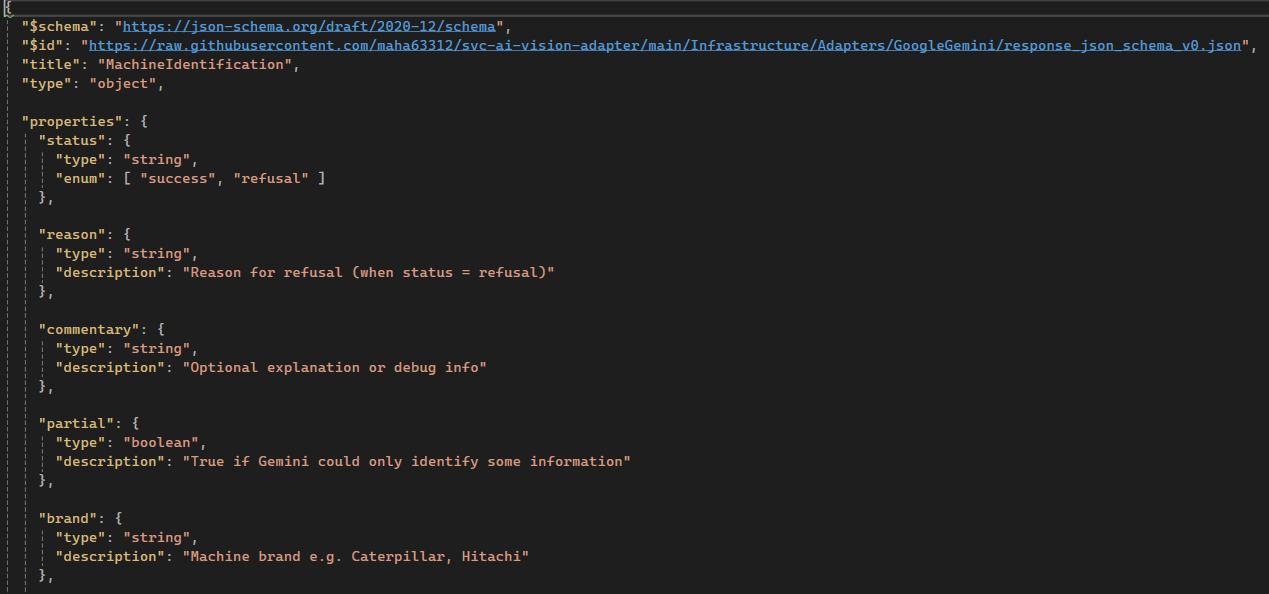
Her ses et udsnit af JSON-schemaet med typer, felter og et enum for statustyperne “success” og “refusal”.
Evaluering af modellerne
Gemini
Fordele:
- Understøtter strict JSON via Structured Outputs
- Hurtig og billig løsning (særligt Flash-modeller)
- God til dataudtræk og klassifikation
Afgrænsninger:
- Mindre stabil i komplekse reasoning-opgaver
- Kræver mere prompt-tuning
Claude 3.5 Sonnet
Fordele:
- Meget stærk i komplekse analyser
- Høj faktuel nøjagtighed
- God struktur i JSON-output
Afgrænsninger:
- Langsommere og dyrere
- Mere forsigtig → flere afvisninger
GPT-4.1
Fordele:
- Stærk reasoning-evne
- Stabil håndtering af schemaer
- Velegnet til klassifikation
Afgrænsninger:
- Kan “overforklare” uden strikt schema
- Ikke helt så konsistent som Claude i lange dokumenter
Praktisk afprøvning og erfaringer
Under testen af Gemini 2.5 oplevede jeg flere “503: Service Unavailable”, som tyder på midlertidig overbelastning.
Billede
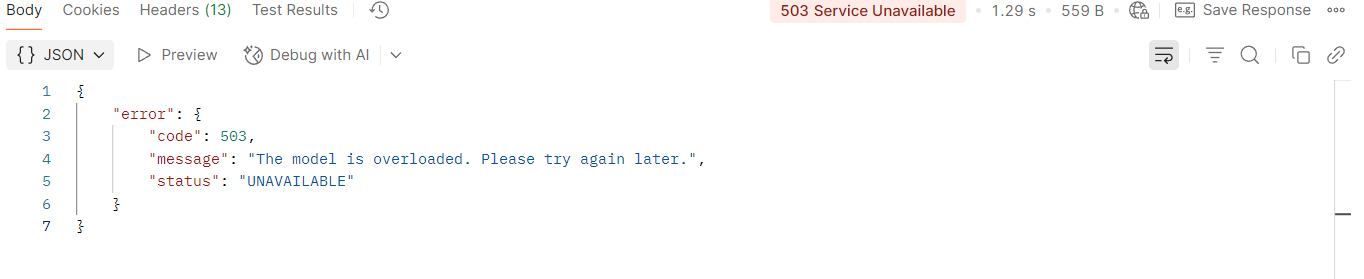
Derfor skiftede jeg til Gemini 1.5, der var mere stabil – men som ikke understøtter strict JSON.
Billede

Første version af prompten (PromptV0) gav chain-of-thought-lækage. Det blev løst ved at tilføje anti-CoT-instruktioner.
Billede

Dette viser, at arbejdet med LLM’er kræver teknisk forståelse for modellens begrænsninger og evnen til at iterere på prompts og schemaer. Kombinationen af AI-kompetencer og backend-viden er afgørende for at skabe robuste løsninger.
Læring / refleksion
Arbejdet med evaluering af LLM-modeller og reduktion af hallucinationer har givet mig en dybere forståelse af, hvordan AI-modeller opfører sig i praksis – og især hvordan man designer backend-arkitektur, der kan håndtere de usikkerheder, som AI introducerer.
Jeg har især lært:
- hvordan forskellige LLM’er håndterer strukturerede outputs, og hvorfor JSON-schema er afgørende for robuste AI-integrationer
- hvordan stramme prompts, kontekst og anti-CoT-instruktioner reducerer risikoen for hallucinationer
- hvorfor modelsammenligning handler om stabilitet, pris, konsistens og schema-overholdelse – ikke kun kvalitet
- hvordan backend-design (DTO’er, mapping, guardrails, validering) kan kontrollere og stabilisere AI-output
- at iteration over prompts, schemaer og parsing er en naturlig del af AI-udvikling og ikke et tegn på fejl
Refleksionen over sammenhængen mellem AI-adfærd og systemdesign har gjort det tydeligt, at en LLM bør ses som et udskifteligt modul i arkitekturen, ikke som en ustabil kernekomponent. Det har styrket min forståelse af, hvordan man bygger systemer, der er både fleksible og driftssikre, selv når de integrerer avanceret AI.
Videre plan
Uge 45: Implementere LLM ved at refaktorere HLD og LLD.