Uge 39 – Smoke Testing
Dato: 26-09-2025 | Uge: 39
Kontekst
Backend-udvikling og API-designMachine Learning og AIProces og læringsmål
Mål
Vurdere hvordan resultaterne fra AI-billedklassifikationstjenesten skal behandles og vægtes i en samlet vurdering.
Skrive tests, der kan validere og verificere output fra analysedelen i microservicen.
Proces
Orientere mig i, hvad der bliver returneret af Google Vision API (GVC), når der sendes en request.
Følge op på krav ift. hvilket resultat der giver mening at returnere til brugeren.
Lave en smoke test for at vurdere funktionaliteten i de metoder, der skal behandle det JSON-materiale, der returneres.
Reflektere over den implementerede kode og om den lever op til de krav, der er opstillet.
Resultat
Når der sendes en request til GVC, har jeg på forhånd bestemt hvilke features billedet skal vurderes på.
Det vil sige, at jeg allerede har gjort mig nogle overvejelser om, hvad der skal til for at lave et tilfredsstillende resultat ift. de krav, der er stillet.
Et af PO’s krav er, at “Servicen skal kunne kategorisere typen af maskine”.
GVC har flere features, som kan være med til at gøre dette.
Som udgangspunkt har jeg startet med disse features:
- LabelDetection: Kan finde objekter, lokationer, aktiviteter, dyrearter, produkter og mere.
- LogoDetection: Finder kendte produktlogoer i et billede, f.eks. Caterpillar.
- DocumentTextDetection: God til at aflæse store dokumenter og udlede tekst fra disse.
- ObjectLocalization: Finder objekter på billedet samt hvordan objektet er placeret.
- WebDetection: Finder labels og beskrivelser fra lignende billeder på nettet.
Kan identificere ens billeder, billeder der kun har dele af det indsendte billede, eller billeder der ligner.
Den returnerer også best guess labels og URLs til lignende billeder.
I vores use case (se HLD her) skal servicen kunne “Klassificere og genkende indhold i billeder”.
For at teste resultatet har jeg først brugt Postman og set hvilket JSON-materiale, der returneres fra GVC.
Det er tydeligt, at der returneres meget data, så jeg vælger at normalisere resultatet ved hjælp af GoogleResultShaper, og oversætter det til en egen model ShapedResultDto.
På den måde får jeg et ensartet resultat, som er provider-agnostisk.
Flow i applikationen
Når resultatet returneres fra Adapter-laget (GoogleVisionAnalyzer), tager min Application Service (RecognitionService) resultatet og sender det videre til interfacet IResultShaper.
GoogleVisionAnalyzer(Adapter) → returnerer råt GVC-resultat.GoogleResultShaper(Adapter) → normaliserer resultatet til intern model (ShapedResultDto).RecognitionService(Application) → koordinerer kald mellem adaptere og aggregator.ResultAggregatorService(Application) → samler og komprimerer resultater, fjerner dubletter, udregner gennemsnitlig confidence og returnerer “Top N” vigtigste fund.
Dette flow er essentielt i use casen, da der forventes et kompakt resultat med metadata, der identificerer maskinen på billedet.
Til at teste dette har jeg derfor lavet en Smoke test, som har til formål at evaluere grundlæggende funktionalitet i applikationen.
Resultater fra første testkørsel
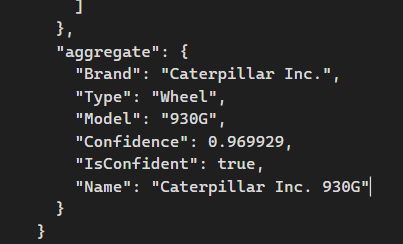
Som man kan se under Type, har den klassificeret maskinen som et “Wheel” (hjul).
Det er korrekt, men vi er interesseret i hele maskinen, ikke kun dele. Derfor justerer jeg features fra LabelDetection, som var min umiddelbare kilde til at bruge WebEntities fra WebDetection til at sætte maskintype, for at se om dette gør en forskel.
Derudover tilføjer jeg et hash, så den returnerer en maskintype jeg har sat ind eller null.

Jeg har også indført to typer confidence i resultatet:
- TypeConfidence: Hvor sikker modellen er på typen (f.eks. “Loader”).
- Confidence: Kan fortælle noget om model sikkerhed ift. hvad den kan udlede fra billedet, altså billedkvalitet. Denne udledes fra ObjectLocalization.
Jeg genovervejede også DocumentTextDetection, der var med i tilfælde af, at der er billede af en tekstfyldt side, men da dette ikke er en del af use casen, har jeg i stedet valgt den lettere TextDetection.
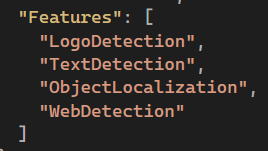
Efter justeringerne endte smoketesten med dette komprimerede resultat:
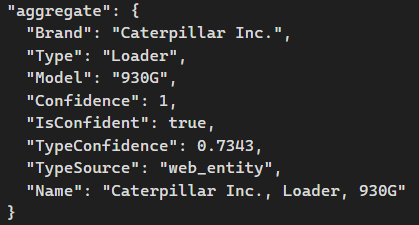
Billedet er en Caterpillar 930G Wheel Loader.
Model-sikkerheden er god med en confidence på 0.9 og typesikkerheden på 0.73.
Efter shaping og komprimering returneres: “Caterpillar Inc., Loader, 930G”.
GVC er altså rigtig god til at finde det samme billede, jeg har brugt som testobjekt.
Næste skridt bliver at se, hvordan servicen klarer sig med billeder, jeg selv har taget og uploadet.
Refleksion (Kolbs læringscirkel)
Undervejs kan jeg tydeligt se, hvordan jeg bevæger mig igennem Kolbs læringscirkel (se her):
- Jeg starter i aktiv eksperimentering (implementering).
- Derefter får jeg konkrete erfaringer, som jeg reflekterer over.
- I den abstrakte konceptualisering omsætter jeg refleksionerne til nye ideer.
- Til sidst går jeg tilbage i aktiv eksperimentering for at verificere de nye ideer.
Jeg kan også se, at processen afspejler Feed-up (mål), Feedback (test) og Feedforward (læring og omskrivning).
Dette vil jeg uddybe mere i en post i løbet af den næste 14 dages periode.
Videre plan
Uge 40: Færdigskrive om fordele og ulemper ved at anvende microservices kontra en monolitisk arkitektur. Lave nye læringsmål for de næste 14 dage.